一、改造

模块一:评估与规划 (对应总流程的“兼容性评估”和“资源评估”)
模块原文:
1. 先解释这个模块里的“黑话”:
- 数据库对象 (Database Objects):可以理解为老房子(Oracle数据库)里所有的“东西”,不只是家具,还包括房子的结构。具体来说就是:
- 表 (Table):存放数据的“柜子”或“抽屉”。
- 索引 (Index):为了快速找到柜子里东西而做的“标签”或“目录”。
- 视图 (View):一个虚拟的“窗户”,让你只看到你想看的部分数据。
- SQL (Structured Query Language):这是你和数据库沟通的“语言”。比如你对数据库说:“请把‘客户’这个柜子里,所有姓‘张’的人的电话号码拿给我”,你说的这句话就是SQL。
- oma (OceanBase Migration Assessment):这是OceanBase官方提供的一个“专业评估工具箱”。它就像评估师手里的各种高科技仪器,能自动扫描你的老房子,生成一份详细的报告。
2. 再说明它们和模块目标的关系:
这个模块的目标是“兼容性评估”和“资源评估”。
- 如何做“兼容性评估”?
- 通过第1点实现:评估师使用oma这个工具箱,去扫描你老房子里所有的“东西”(数据库对象)和你的“做事习惯”(SQL语言),然后告诉你:“你的这张沙发(某个数据库对象)尺寸太特殊,新家放不下”、“你以前习惯这么喊管家(某种SQL写法),新管家听不懂”。这就是兼容性分析,提前找出所有可能不匹配的地方。
- 如何做“资源评估”?
- 通过第2点实现:评估师会检查你老房子(Oracle)过去一年的水电费账单,看看你家高峰期要用多少电、多少水(CPU、内存、硬盘等资源)。这样他就知道,你的新别墅(OceanBase)要配多大的发电机和水箱才够用,不能建小了,也不能浪费。
模块二:改造与准备 (对应总流程的“去Oracle依赖”、“应用拆分”、“SQL优化”、“对象设计调整”)
模块原文:
1. 先解释这个模块里的“黑话”:
- 存储过程 (Stored Procedure), package:这是Oracle独有的“高级定制家具”,比如一个和墙体融为一体的、带自动上菜功能的餐桌。它很好用,但是你根本搬不走。它和Oracle数据库绑得太死了。
- 主键 (Primary Key):给每个东西贴的“唯一身份证号”。比如“客户表”里,每个客户都有一个独一无二的客户ID,这就是主键。这在新家里是必须的,能保证数据不混淆。
- 大表分区 (Partitioning):想象你有一个装了几万件衣服的超大衣柜(大表),找一件衣服要翻半天。分区就是把这个大衣柜改造成很多个小抽屉,并贴上标签,比如“春季-上衣”、“夏季-裤子”。这样找衣服就快多了。
- join:当你要找的数据分散在两个或多个“柜子”(表)里时,你需要把这些柜子里的信息“拼接”起来看。比如,“订单”柜子里有客户ID,但客户电话在“客户”柜子里,你需要把这两个柜子的信息join一下才能看到一个完整的订单信息。复杂的join就像要同时打开十几个柜子找东西拼凑信息,非常慢。
2. 再说明它们和模块目标的关系:
这个模块的四大目标,就是由这四条具体操作实现的:
- 为了“去Oracle依赖”:我们必须“去除存储过程、package”这些搬不走的定制家具,用所有数据库都支持的标准化方法来重写它的功能。
- 为了“应用拆分”:我们“按功能场景拆分应用”,把原来一个庞大的软件系统,拆成“管订单的”、“管客户的”等几个独立的小系统
- 为了“对象设计调整”:我们进行“表结构调整”,比如给没身份证的东西补上“主键”;把超大的衣柜(大表)改造成带标签的小抽屉(分区);重新整理“索引”(目录),让新家的数据存放得更科学。
- 为了“SQL优化”:我们“重写复杂sql,减少join”,把原来那种需要翻十几个柜子的低效“查询指令”,改成只需要查两三个柜子的高效指令,提升速度。
模块三:数据迁移 (对应总流程的“数据库瘦身”、“数据增量准实时同步”等)
模块原文:
1. 先解释这个模块里的“黑话”:
- 存量历史数据 (Existing Data):你家已经存在的所有家当,是你搬家前那一刻所有的东西。
- 在线新增数据 (Incremental Data):在你搬家期间(可能持续几天),你又网购了新东西,快递员还往你老房子送。这些就是“新增数据”。
- 并行 (Parallel):意思是“同时进行”。搬家时只叫一辆车是“串行”,叫十辆车同时搬不同房间的东西,就是“并行”。
- 停机窗口 (Downtime Window):指你的业务“暂停服务”的时间。比如银行系统升级,会通知你“周日凌晨2点到4点本行App无法使用”,这2个小时就是停机窗口。目标是让它越短越好,甚至是零。
2. 再说明它们和模块目标的关系:
这个模块的核心目标是实现平稳、高效的数据同步。
- 第一步是处理“存量数据”:先把老房子里所有东西打包搬家(存量历史数据先迁移),顺便把没用的垃圾扔掉(无用数据清理),这对应了总流程里的“数据库瘦身”。
- 第二步是处理“增量数据”:为了不影响正常业务,老房子在搬家期间还在收快递(产生新数据)。我们用oms这个工具,像装了个监控一样,只要老家一来新快递,就立刻复制一份送到新家,做到“准实时同步”。这样保证了两个房子的东西时刻保持一致。
- 第三步是提升效率和减少影响:为了让搬家更快,我们采用了“并行”的策略,比如对于那个分区改造过的“超大衣柜”,我们派10辆车,每辆车负责搬运一个“小抽屉”的数据,这就是“按大表拆分多条同步链路”。因为搬得快,而且新旧数据实时同步,整个切换过程就不需要长时间“暂停服务”,极大地“减少了停机窗口”。
模块四:上线前测试 (对应总流程的“只读接口流量切换”和“抽数并行对比”)
模块原文:
1. 先解释这个模块里的“黑话”:
- 只读应用 (Read-only Application):指的是那些“只看不动”的操作。在银行App里,查询余额、查看交易记录就是典型的“只读”操作,因为它不会改变你账户里的钱。相反,“转账”就是“读写”操作,因为它会修改你和对方的余额。
- 流量 (Traffic):在互联网世界里,指的就是用户的访问请求。银行App的“流量”,就是成千上万个用户同时在上面进行查询、转账等操作的请求流。
- 大数据抽数任务 (Big Data Extraction Task):一个自动化的、大规模的数据核对程序。它不是人工一个个地看,而是像一个超级审计机器人,能瞬间从两个数据库里抽取海量数据进行比对。
- 数据一致性 (Data Consistency):这是数据库领域的生命线,意思是确保新、旧两个数据库在同一时间点的数据是一模一样、分毫不差的。
2. 再说明它们和模块目标的关系:
这个模块的目标是“双重验证,确保万无一失”。它通过两条路径来达成这个目标:
- 路径一:真实场景演练,验证“功能”与“性能”(由第1点实现)
- 验证功能: 我们把一部分“只读”的流量(比如只让尾号为8的用户的所有查询请求)切换到新的OceanBase数据库上。这样做是为了看看新系统在真实用户的使用下,功能是否正常。比如,用户查余额时,显示的页面对不对?查交易记录时,会不会报错?
- 验证性能: 同时,这也是一次压力测试。当成千上万的真实请求涌入时,新系统(OceanBase)会不会卡顿?响应速度快不快?
- 路径二:数据全面审计,验证“数据一致性”(由第2点实现)
- 在进行真实场景演练的同时,我们启动了“大数据抽数任务”。这个任务在后台默默地、并行地(同时)从老的Oracle库和新的OceanBase库里海量抽取数据进行比对。它不关心页面好不好看,只关心最底层的数据是不是100%一致。
二、ECIF生产架构
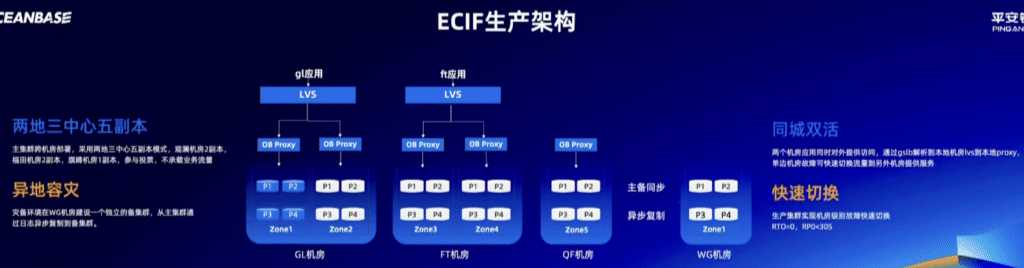
概念
- ECIF (Enterprise Customer Information Facility): 企业级客户信息系统。这是银行的“户口本”,记录了所有客户最核心的信息(你是谁,你的身份证号,你的所有账户等)。这是银行最最关键的系统之一。
- 生产架构 (Production Architecture): 指的是正在为真实用户提供服务的、在线运行的系统,而不是测试或开发系统。
- 机房 (Data Center): 存放大量服务器的物理建筑。图中的 GL、FT、QF、WG 都是不同机房的名字/代号。
- 副本 (Replica): 就是数据的完整拷贝。一份数据存5个副本,就意味着同样的数据被复制了5份,存在不同的地方。
- Zone: 在OceanBase里,一个Zone可以理解为一个机房内独立的“服务器小组”,它有独立的供电和网络,这样即使一个小组出问题,也不会影响其他小组。
架构流程说明
ECIF生产架构 (银行客户户口本的在线系统架构)
核心目标:极致的高可用和数据安全。
整体布局:两地三中心五副本 & 异地容灾
- 我们有四个机房:GL、FT、QF在同一个城市(比如深圳),WG在另一个城市(比如上海)。
- 最核心的客户数据(ECIF)被复制了5份(P1-P5),分布在GL、FT、QF这三个机房里,GL机房有2个副本,FT机房有2个副本,QF机房有1个副本。
- 主集群 (Primary Cluster) 指的是当前正在线上提供服务的、活的、主要的数据库系统。它处理所有用户的实时请求(转账、查询等)。它存放的数据确实是主要数据,是系统的“正本”。这个主集群一共有5个副本。这5个副本的数据是实时强一致的。
- 构成了“同城三中心五副本”的主集群。比异地容灾更低一个级别的容灾机制
- 同时,我们在远在上海的WG机房建立了一个独立的备集群。主集群通过“异步复制”的方式,把数据复制到WG机房。这就实现了“异地容灾”。
- 备集群存放的是主集群数据的完整拷贝!唯一目的就是灾难备份。您可以把它想象成主集群的一个“影子”或者“备胎”。它在平时是不直接对外提供服务的,只是默默地在后台接收从主集群同步过来的数据。它的数据必须和主集群保持一致(或尽可能一致)。特指异地容灾备份。因为一旦主集群所在的整个城市(深圳)发生了毁灭性灾难,我们就需要启动这个在上海的备集群,让它“转正”成为新的主集群。
- 总结两个复制过程:复制的不是“副本”,而是“数据本身”。
在主集群内部(深圳的三个机房之间):
- 当有一笔数据要写入时,是先写到5个副本中的一个Leader副本上。
- 然后,这个Leader副本会把这个“数据变化”通过“主备同步”的方式,发给其他4个副本。这个过程保证了深圳的5个副本之间,数据是完全一模一样的。
从主集群(深圳)到备集群(上海):
- 主集群会把所有确认完成的“数据变化”(也叫日志),通过“异步复制”的方式,源源不断地传送到上海的备集群。
- 上海的备集群接收到这些“数据变化”后,在自己的系统里进行重放,从而让自己的数据跟上主集群的步伐。
- 所以,可以理解为:主集群(深圳)把一份完整、持续更新的数据流,复制到了备集群(上海)。备集群内部为了自身的高可用,也可能会设置多个副本(比如3个),但这与从深圳到上海的复制过程是两回事。
日常工作模式:同城双活
- 在深圳的GL机房和FT机房,它们是“双活”的。意思是,两个机房的服务器都在7×24小时地处理真实的业务请求。
- 一个用户的请求是怎么被处理的? (我们以gl应用为例)
- 第一步:一个用户的请求(比如查余额)先到达LVS
- 第二步:LVS把这个请求随便发给一个不忙的OB Proxy
- 第三步:OB Proxy收到请求,它非常聪明,知道这5份数据副本(P1-P5)具体在哪几台服务器上,于是它直接去对应的服务器(比如Zone1里的P1)拿数据。
- 第四步:拿到数据后,原路返回给用户。
故障应对模式:快速切换
- 场景一:同城机房故障(比如GL机房整个断电了)
- 由于是“同城双活”,FT机房本来就在工作,所以LVS会瞬间发现GL机房的OB Proxy都联系不上了,于是它会自动把所有新的用户请求都只发往FT机房。
- 数据库层面,因为数据有5个副本,GL机房的2个副本虽然挂了,但FT和QF机房还剩下3个副本,超过了半数(2.5),系统依然可以正常读写,数据一点都不会丢。
- 这个切换过程是全自动的,几乎是瞬时完成。这就是RTO=0的由来。
- 场景二:整个深圳都瘫痪了(极端灾难)
- 这时,我们需要手动启动“异地容灾”预案。
- 我们会把所有业务流量切换到上海的WG机房。
- 因为主备之间是“异步复制”的,所以WG机房的数据可能会比深圳瘫痪前的数据落后几秒到几十秒。这就是RPO < 30S的含义——我们可能丢失最多30秒的数据,这对于金融系统来说已经是极高级别的容灾能力了。
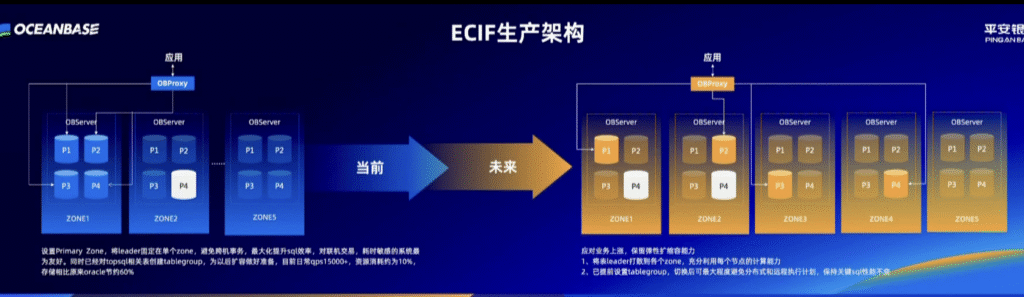
核心概念
- OBServer: 指OceanBase数据库集群里的单个服务器节点。图里每个大方框(Zone)里的小方框(OBServer)就是一台装了OceanBase软件的服务器。
- Leader 副本: 这是理解这张图的关键!
- 我们知道一份数据有多个副本(比如P1, P2, P3, P4…),但为了保证数据的一致性,在任何一个时刻,这多个副本里只有一个是“老大” (Leader),其他都是“小弟” (Follower)。
- 所有的“写”操作(比如转账、修改信息)都必须由这个Leader副本首先处理,然后再由它同步给所有小弟。
- “读”操作可以由Leader或Follower处理,但读Leader能保证读到最新的数据。
- Primary Zone: 主可用区。在OceanBase里,可以指定一个Zone为Primary Zone,这意味着在正常情况下,所有数据的Leader副本都会优先集中在这个Zone里。
- 跨机房事务: 指一个操作(事务)需要同时读写分布在不同机房的服务器上的数据。这种操作因为需要网络传输,延迟会比较高,效率较低。我们总是希望尽可能避免它。
- tablegroup (表组): 这是OceanBase的一个优化功能。它可以把几张关联性很强的表(比如“订单表”和“订单详情表”)“捆绑”在一起,确保这些表的数据会落在同一台服务器上。
- 好处:当查询需要同时用到这几张表时,就不需要跨服务器去查找了,直接在一台机器内部完成,速度极快。
- qps (Queries Per Second): 每秒查询率。这是衡量数据库处理能力的重要指标,qps越高,说明数据库越强大。qps15000+ 意味着这个系统每秒能处理超过15000次查询请求。
- 弹性扩缩容: 指可以根据业务量的变化,方便地增加或减少服务器数量的能力。业务高峰期加机器,低谷期减机器,节约成本。
- 分布式执行计划 / 远程执行计划: 当你要查询的数据分散在不同的服务器上时,数据库需要制定一个“计划”,先去A服务器拿一部分数据,再去B服务器拿另一部分,最后汇总起来。这种跨服务器的计划就叫分布式/远程执行计划,效率比在一台机器内完成要低。
第二部分:架构演进流程说明
这张图的核心思想是:从“为读优化”的集中式Leader架构,演进到“为写和扩展优化”的分布式Leader架构。
“当前”的架构状态:集中式Leader,读性能最大化
1. 架构描述:
- 系统部署在3个Zone(可以理解为3个机房或3组服务器)。
- 关键点:设置Primary Zone,将leader固定在单个zone。看图可知,ZONE2里的P4副本是白色的,而其他副本是蓝色的,这暗示了所有数据的Leader副本都集中在ZONE2这一个可用区里。
2. 这种架构的“好处”:
- 避免跨机房事务,最大化提升sql效率: 因为所有“写”操作都由ZONE2里的Leader处理,而“读”操作也可以优先发往ZONE2,所以大部分操作都在一个机房内完成,速度非常快。这对于**“对联机交易、耗时敏感的系统”**(比如要求极速响应的银行柜台业务)非常友好。
- 已经做了基础优化:
- 通过tablegroup把相关表捆绑在一起,进一步提升了查询性能。
- qps15000+ 说明当前性能已经很强。
- 资源消耗约为10%,存储相比原来oracle节约60%,说明系统效率很高,成本控制得很好。
3. 这种架构的“潜在问题”:
- ZONE2压力过大: 所有的写压力都集中在ZONE2,它的服务器资源会成为整个系统的性能瓶颈。
- 扩容不便: 如果业务量暴增,光给ZONE2加机器可能不够,而且也无法充分利用ZONE1和ZONE3的计算资源。
“未来”的演进方向:分布式Leader,为扩展性和业务上漲做准备
1. 架构描述:
- 系统扩展到了5个Zone,保留了弹性扩缩容能力。
- 关键点:将表leader打散到各个zone,充分利用每个节点的计算能力。看图可知,ZONE1的P1、ZONE2的P2、ZONE4的P3都变成了橙色,这代表不同数据的Leader副本被均匀地分散到了不同的Zone里。
2. 为什么要这么演进?
- 应对业务上涨: 随着用户增多,写请求会暴增。把Leader分散开,就等于把“写”的压力分摊给了所有机房,不再是ZONE2一个地方扛着了。
- 充分利用资源: 每个Zone都有服务器,每个服务器都有CPU。让每个Zone都承担一部分Leader的写任务,就能把所有服务器的计算能力都用起来,避免了资源浪费。
3. 怎么保证性能不下降?
- 关键点:已提前设置tablegroup,切换后可最大程度避免分布式和远程执行计划,保持关键sql性能不变。
- 解释: 虽然Leader被打散了,可能会增加跨机房操作的风险。但是,因为我们提前用tablegroup把高度相关的表(比如一个客户的所有账户信息)捆绑在了一起,所以同一个客户的所有操作,其涉及到的Leader副本大概率还是在同一个Zone里。这样,虽然整个系统的Leader是分散的,但针对单个业务场景的查询,依然可以在一个机房内部完成,从而避免了性能下降。
总结整个演进流程
平安银行的ECIF系统架构演进,是一个深思熟虑的、分两步走的优化过程:
- 第一阶段(当前):“求稳求快”
- 将所有Leader副本集中在一个主可用区(Primary Zone),牺牲了一部分可扩展性,换来了极致的读写性能和最低的延迟。这在系统上线初期,为了保证核心交易的绝对稳定和快速响应,是非常明智的选择。
- 第二阶段(未来):“拥抱增长”
- 在系统稳定运行、业务量持续增长的背景下,开始为未来的大规模扩展做准备。通过打散Leader副本到所有可用区,将写入压力均匀分摊,充分利用所有服务器资源,获得近乎无限的水平扩展能力。
- 同时,利用tablegroup等高级特性,巧妙地规避了Leader分散可能带来的性能衰减问题,做到了“鱼和熊掌兼得”。
这个演进体现了架构设计的艺术:在不同的阶段,根据核心矛盾的不同,采用不同的策略,并为下一阶段的演进提前做好准备。
33.6s
more_vert
Leave a Reply