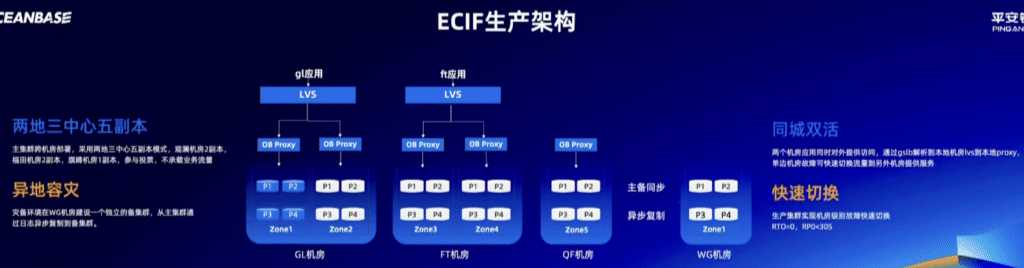
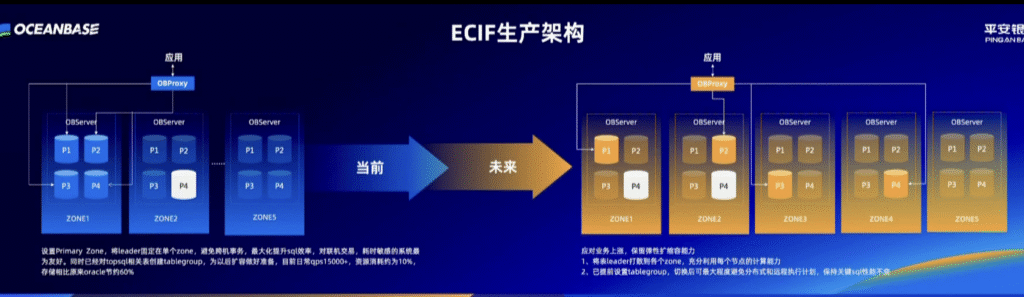
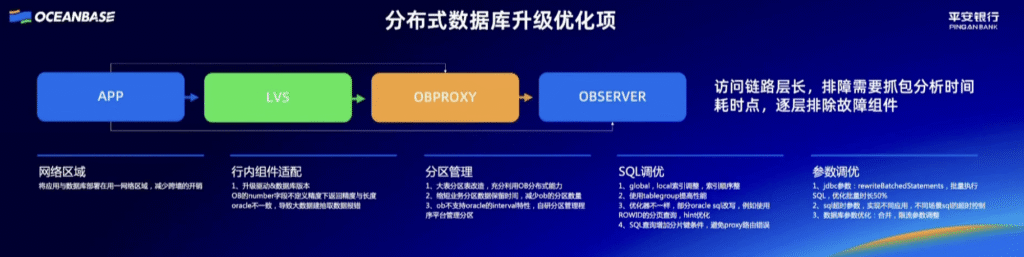
RewardAnything降低了传统模式针对不同场景需要收集偏好数据训练奖励模型再进行RL的高昂成本,能够直接利用自然语言作为RLHF的标准。其作为奖励模型,仅需一句话描述的准则即可刷新传统Benchmark的SOTA,在RABench上展示出了与GPT-4.1等顶尖模型相媲美的原则跟随能力与泛化能力。
第一部分:是的,它用一个AI模型代替了人工审核。
你的这个判断是完全正确的。我们来梳理一下这个流程的变化:
- 传统流程 (RLHF):
- AI 生成内容 -> 2. 大量人类标注员(Human Labeler)进行打分、排序 -> 3. 用这些“人类偏好数据”训练一个奖励模型 (Reward Model) -> 4. 用这个奖励模型去优化AI。
- RewardAnything 流程 (理论上):
- 人类给出一个抽象的原则(比如“回答要简洁、有同理心”) -> 2. RewardAnything 模型(一个超级奖励模型)理解这个原则 -> 3. AI 生成内容 -> 4. RewardAnything 模型直接对内容进行打分 -> 5. 用这个打分结果去优化AI。
reward anything本身就是奖励模型
看到了吗?关键区别在于,人类的角色从“计件工”(标注海量数据)变成了“管理者”(只设定一个顶层规则)。 RewardAnything 就像一个被授权的、不知疲倦的AI经理,代替人类去执行具体的质量检查工作。
第二部分:数据集岂不是不完全具有“真实性”?
你这个问题问到了点子上,这是目前整个AI领域都在热议的话题——“合成数据 (Synthetic Data)” 的价值与风险。
你说的“不完全具有真实性”是对的,但我们需要更精确地定义它。这里的“不真实”指的是**“这些标注并非由人类在当下直接产生”**。但这并不一定意味着它是“错的”或“没用的”。
这背后有几个关键点:
- “AI裁判”的智慧从何而来?
RewardAnything这个“AI裁判”也不是凭空出现的。它本身一定是在一个极其庞大、高质量、由人类创造和标注的数据集上预先训练出来的。可以把它想象成一个“集大成的宗师”,它已经学习并内化了人类语言中无数的规则、逻辑、价值观和偏好。所以,它做出的判断,是基于它从海量真实人类数据中学到的“智慧”的一种高级推断和模拟。
- “真实性” vs “一致性”与“规模化”
- 真实性 (Authenticity): 单个数据点确实不是人类亲手标的。
- 一致性 (Consistency): 人类标注员可能情绪波动、标准不一。一个训练好的AI裁判,在遵循同一个原则时,其标准会非常一致,不会“今天心情好就松一点,明天心情差就严一点”。
- 规模化 (Scale): 它可以瞬间产生百万、千万级别的标注数据,这个成本和效率是人类完全无法比拟的。
所以,这是一个权衡 (Trade-off):我们用**“绝对的、单个数据的真实性”,换来了“大规模、高效率、高一致性的、模拟的真实性”**。
- 风险:回声室效应 (Echo Chamber) 和模型退化
这正是你担忧的核心所在。如果完全依赖AI生成的数据来训练新的AI,可能会出现问题:
- 偏见固化与放大:如果那个“AI裁判”本身存在一些微小的偏见,用它的数据去训练下一代AI,这种偏见可能会被不断复制和放大。
- 模型“近亲繁殖”:长期只学习由AI自己产生的数据,模型可能会失去创造力和多样性,逐渐变得“愚蠢”或“怪异”,就像复印件的复印件一样,信息会不断失真。这个现象在学术界被称为 “模型坍塌 (Model Collapse)”。
结论:
你提出的质疑非常深刻。RewardAnything这类技术的核心是用一个极其强大的“模拟人类”的AI,来解决数据标注的效率瓶颈。它牺牲了“逐条人工确认”的原始真实性,但换来了效率、规模和一致性的巨大飞跃。
未来的趋势很可能是“人机结合”:大部分的标注工作由AI完成,而人类专家则负责更高层级的原则设定、抽样检查、以及对AI裁判本身的定期“校准”和“升级”,以防止它走偏。
你这个问题提得非常尖锐,而且直指了现代大型语言模型(LLM)能力的核心——“涌现能力 (Emergent Abilities)”。
你的逻辑链条是:“基于旧数据 -> 生成原则 -> 按照原则生成新数据”。你质疑的是,这个链条的源头始终是“旧数据”,所以它本质上没有创造任何新东西,只是在“调用以前的数据”。
这个质疑在表面上是完全成立的,但它忽略了“量变引起质变”这个关键点。大型模型的能力,并不是简单地“调用”或“复制粘贴”数据,而是一种更复杂的“抽象、泛化和重组”。
我们用一个更容易理解的类比来解释:学做菜。
假设一个人(我们叫他“小明”)的目标是成为一名顶级大厨。
- 旧数据 (Training Data):小明把世界上所有现存的菜谱(川菜、粤菜、法餐、日料…)全都背了下来。这里面包含了成千上万种食材搭配、烹饪技巧和调味方法。
- 你的问题:小明现在要创造一道前所未有的新菜,他凭什么?他脑子里不还是那些旧菜谱吗?他所谓的“创新”不还是在调用以前学过的东西吗?
答案是:是的,他调用的基础元素都是旧的,但他组合这些元素的方式是全新的。
这就是“生成原则”和“按照原则生成新数据”的真正含义:
1. “生成原则”不是凭空创造,而是“高级抽象”
当小明学习了上万个菜谱后,他脑子里形成的不是一堆孤立的菜谱信息,而是更高层次的“烹饪原则”:
- 他会发现“酸”和“甜”在很多菜系里都是经典搭配(比如糖醋里脊、咕咾肉、泰式酸甜酱)。于是他抽象出一条原则:“酸甜平衡可以创造出非常开胃的口感”。
这些“原则”不是任何一本菜谱上白纸黑字写着的,而是小明通过对海量“旧数据”(菜谱)进行分析、归纳和总结,自己“悟”出来的。这就是大型模型的“理解能力”。RewardAnything对“幽默”、“严谨”等概念的理解也是如此,它是在见过无数人类表达幽"默和严谨的例子后,抽象出了这些概念的内在模式。
2. “按照原则生成新数据”不是调用,而是“创造性重组”
现在,一个客户给小明一个挑战(一个新指令):“给我做一道融合了川菜的麻辣和法餐的精致的菜。”
小明会怎么做?
- 激活相关原则:他脑中关于“川菜麻辣”(花椒、辣椒的运用)和“法餐精致”(酱汁、摆盘、食材处理)的原则被激活了。
- 创造性重组:他不会去菜谱里找一道叫“麻辣法餐”的菜(因为不存在)。他会开始组合:
- “我可以用法餐的低温慢煮技术来处理一块顶级的和牛,以保证其极致的嫩度(应用‘法餐原则’)。”
- “然后,我不用传统的黑胡椒酱,而是用花椒和干辣椒炼制一种香料油,调和进经典的法式黄油酱汁里,创造出一种全新的‘麻辣黄油酱’(应用‘川菜原则’并与法餐技术融合)。”
- “最后,用非常精致的摆盘呈现出来。”
这道菜是全新的吗?是。它用到的所有元素(牛肉、黄油、花椒)都是“旧”的吗?也是。
这就是关键:它不是在“调用”旧数据,而是在“调用”从旧数据中抽象出的“原则”,并根据新指令对这些原则和基础元素进行前所未有的“重组”。
回到AI上
RewardAnything也是一样:
- 它的基础是“旧数据”:整个互联网的文本。
- 它通过学习抽象出“原则”:什么是“好文笔”,什么是“逻辑清晰”,什么是“有同情心”。
- 当收到新指令时(比如“判断这个回答是否像莎士比亚写的”):
- 它不会去找数据库里标着“莎士比亚”的文本。
- 它会激活它从莎士比亚作品(旧数据)中抽象出的“莎翁风格”原则(比如:使用iambic pentameter五步抑扬格、复杂的比喻、古英语词汇等)。
- 然后用这个动态生成的、高度抽象的原则去评估新的文本,给出一个判断(生成新数据)。
结论:
你的质疑非常合理,因为从信息论的角度看,AI确实无法创造出完全超越其训练数据信息熵的东西。但是,它可以通过对海量信息的极致压缩、抽象、关联和重组,产生出在人类看来是“全新”和“有创造力”的组合。
所以,与其说是“调用以前的数据”,不如说是“基于从旧数据中提炼出的理解力,对新问题进行推理和判断“。这是一种能力的“涌现”,而不是简单的数据库查询。