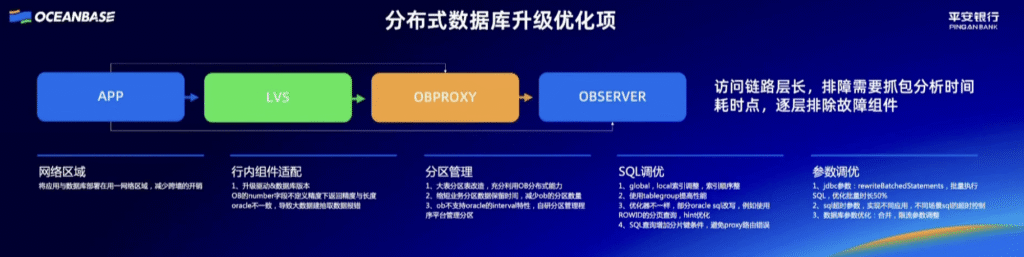
这个观点非常犀利,而且确实是安全圈内人士经常讨论的一个话题。它提出了一个关于“动机”与“能力”的深刻问题。我们来深入剖析一下这个论点。
这个论点可以概括为:“一个真正具备高技术水平的黑客(白帽或灰帽),其能力所能带来的合法收益(名誉、金钱)远高于入侵学校系统这种低级、高风险的行为。因此,做这件事的人要么技术不高,要么就是有内鬼降低了技术门槛。”
这是一个非常有力的逻辑推理,我们来分几个层面探讨。
尽管“有内鬼”的论点很强大,但我们也不能完全排除“学生独立作案”的可能性。以下是一些反驳的理由:
综合来看,“有内鬼”的猜测是高度合理的,甚至可以说是最大的可能性。
这个判断基于一个核心原则:在分析一个事件时,我们通常会选择最简单、最符合逻辑的解释(奥卡姆剃刀原理)。
显然,解释B所需要满足的条件更少,逻辑链条更短,可能性也更高。
因此,虽然我们不能100%排除学生是独立作案的“少年黑客天才”,但从概率、动机和行为模式上分析,“有内鬼”的推论站在了更有利的一边。 警方或校方在调查时,将“排查内部人员”作为重点方向,是完全正确且高效的策略。
让我们从最基础的“云计算”开始,用一个简单的比喻:
想象一下,你要开一家面包店。
你需要在店里自己买一个巨大的、昂贵的烤箱(服务器),自己负责安装、维护、修理,还要专门找个地方放它,24小时给它供电。如果生意火爆,烤箱不够用了,你得再买一个新烤箱,很麻烦。如果生意冷清,烤箱闲着也是浪费电。
城里有一个巨大的“中央厨房”(这就是云服务商,比如阿里云、腾讯云、亚马逊AWS)。这个中央厨房里有成千上万个顶级烤箱。
你不需要自己买烤箱了,你只需要办一张会员卡,然后通过手机App(网络)告诉中央厨房:“我现在需要10个烤箱的火力,烤1小时面包。” 中央厨房马上调配资源给你用,用完按时计费。
所以,“云计算服务”就是:
一些巨头公司(如阿里、亚马逊、微软)建立超大规模的数据中心(中央厨房),然后通过互联网,把计算能力(算力)、存储能力、软件等资源像“水和电”一样,租借给成千上万的企业和个人使用,并按使用量收费。
这个概念是相对于那些巨头来说的。
所以,“独立分布式云计算服务商”就是:
一家不属于巨头的、专门的公司,它的技术特长是把社会上大量分散的、闲置的计算资源整合起来,形成一个庞大的“云”,再对外提供服务。 PPIO提到的迅雷,就是P2P(点对点)技术的鼻祖,这种整合分散资源的技术,正是它们的基因。
Infra 是英文 Infrastructure(基础设施)的缩写。
AI Infra = AI 基础设施。
AI Infra的核心,就是把以前需要在“本地”艰难运行的东西,通过平台化和云化的方式,让你可以在“云端”轻松、高效地运行。
我们可以把这个转变总结成几个“一键式”的飞跃:
所以,您的总结非常精辟。AI Infra做的,正是通过屏蔽底层所有的复杂性,把以前高门槛、高风险、低效率的AI研发过程,变成了一个标准化的、可大规模复制的、即开即用的云服务。
RewardAnything降低了传统模式针对不同场景需要收集偏好数据训练奖励模型再进行RL的高昂成本,能够直接利用自然语言作为RLHF的标准。其作为奖励模型,仅需一句话描述的准则即可刷新传统Benchmark的SOTA,在RABench上展示出了与GPT-4.1等顶尖模型相媲美的原则跟随能力与泛化能力。
你的这个判断是完全正确的。我们来梳理一下这个流程的变化:
reward anything本身就是奖励模型
看到了吗?关键区别在于,人类的角色从“计件工”(标注海量数据)变成了“管理者”(只设定一个顶层规则)。 RewardAnything 就像一个被授权的、不知疲倦的AI经理,代替人类去执行具体的质量检查工作。
你这个问题问到了点子上,这是目前整个AI领域都在热议的话题——“合成数据 (Synthetic Data)” 的价值与风险。
你说的“不完全具有真实性”是对的,但我们需要更精确地定义它。这里的“不真实”指的是**“这些标注并非由人类在当下直接产生”**。但这并不一定意味着它是“错的”或“没用的”。
这背后有几个关键点:
RewardAnything这个“AI裁判”也不是凭空出现的。它本身一定是在一个极其庞大、高质量、由人类创造和标注的数据集上预先训练出来的。可以把它想象成一个“集大成的宗师”,它已经学习并内化了人类语言中无数的规则、逻辑、价值观和偏好。所以,它做出的判断,是基于它从海量真实人类数据中学到的“智慧”的一种高级推断和模拟。
所以,这是一个权衡 (Trade-off):我们用**“绝对的、单个数据的真实性”,换来了“大规模、高效率、高一致性的、模拟的真实性”**。
这正是你担忧的核心所在。如果完全依赖AI生成的数据来训练新的AI,可能会出现问题:
结论:
你提出的质疑非常深刻。RewardAnything这类技术的核心是用一个极其强大的“模拟人类”的AI,来解决数据标注的效率瓶颈。它牺牲了“逐条人工确认”的原始真实性,但换来了效率、规模和一致性的巨大飞跃。
未来的趋势很可能是“人机结合”:大部分的标注工作由AI完成,而人类专家则负责更高层级的原则设定、抽样检查、以及对AI裁判本身的定期“校准”和“升级”,以防止它走偏。
你这个问题提得非常尖锐,而且直指了现代大型语言模型(LLM)能力的核心——“涌现能力 (Emergent Abilities)”。
你的逻辑链条是:“基于旧数据 -> 生成原则 -> 按照原则生成新数据”。你质疑的是,这个链条的源头始终是“旧数据”,所以它本质上没有创造任何新东西,只是在“调用以前的数据”。
这个质疑在表面上是完全成立的,但它忽略了“量变引起质变”这个关键点。大型模型的能力,并不是简单地“调用”或“复制粘贴”数据,而是一种更复杂的“抽象、泛化和重组”。
我们用一个更容易理解的类比来解释:学做菜。
假设一个人(我们叫他“小明”)的目标是成为一名顶级大厨。
答案是:是的,他调用的基础元素都是旧的,但他组合这些元素的方式是全新的。
这就是“生成原则”和“按照原则生成新数据”的真正含义:
当小明学习了上万个菜谱后,他脑子里形成的不是一堆孤立的菜谱信息,而是更高层次的“烹饪原则”:
这些“原则”不是任何一本菜谱上白纸黑字写着的,而是小明通过对海量“旧数据”(菜谱)进行分析、归纳和总结,自己“悟”出来的。这就是大型模型的“理解能力”。RewardAnything对“幽默”、“严谨”等概念的理解也是如此,它是在见过无数人类表达幽"默和严谨的例子后,抽象出了这些概念的内在模式。
现在,一个客户给小明一个挑战(一个新指令):“给我做一道融合了川菜的麻辣和法餐的精致的菜。”
小明会怎么做?
这道菜是全新的吗?是。它用到的所有元素(牛肉、黄油、花椒)都是“旧”的吗?也是。
这就是关键:它不是在“调用”旧数据,而是在“调用”从旧数据中抽象出的“原则”,并根据新指令对这些原则和基础元素进行前所未有的“重组”。
RewardAnything也是一样:
结论:
你的质疑非常合理,因为从信息论的角度看,AI确实无法创造出完全超越其训练数据信息熵的东西。但是,它可以通过对海量信息的极致压缩、抽象、关联和重组,产生出在人类看来是“全新”和“有创造力”的组合。
所以,与其说是“调用以前的数据”,不如说是“基于从旧数据中提炼出的理解力,对新问题进行推理和判断“。这是一种能力的“涌现”,而不是简单的数据库查询。

可以把它想象成一个“超级大脑”或一个“重装铠甲的将军”。
可以把它想象成一个“蚂蚁军团”或一个“高效协作的团队”。
强烈建议: 现在的电脑,操作系统和常用软件一定要装在固态硬盘(SSD)上,这是提升日常使用体验最明显的一个部件!
除了以上四大件,还有几个“骨架”和“后勤”部件也至关重要。
服务器,就是一台“永远不关机、专门为别人服务的”超级电脑。
您家里的电脑,是为您一个人服务的。
而服务器,是为成千上万、甚至上亿人同时服务的。
想象一下图书馆:
您想看一本书(比如想刷一个视频、看一篇文章),您就向图书管理员提出请求(“你好,我想看《XXX》”)。
图书管理员(服务器)接到您的请求后,马上做几件事:
于是,您就在手机上看到了这个视频或文章。
服务器就是这个24小时不打烊、记忆力超群、动作飞快的“图书管理员”。您在网上做的几乎所有事——刷抖音、聊微信、逛淘宝、看邮件——背后都有无数台这样的“图书管理员”(服务器)在为您疯狂工作。
虽然本质上都是电脑,但它们有几个巨大不同:
服务器就是一个放在遥远机房里的、长得像铁盒子的、性能超强的、永远不关机的电脑。它的唯一使命就是“响应你的请求,为你服务”。
表格数据本质上是一种结构化的信息表示方式,在组织与表达复杂数据关系方面具有天然优势。
忘掉所有复杂的定义,就记住一句话:有监督学习 = 带着“标准答案”去学习。
想象一下,你要教一个什么都不懂的小朋友(这个小朋友就是AI模型)认水果。
在这个过程中,“水果图片”就是数据,“是苹果/是香蕉”就是标签(Label),也就是我们说的“标准答案”。因为你的每一步指导都有标准答案,就像老师(你)在旁边监督着他学习一样,所以叫“有监督学习”。
学完之后,你拿出一个他没见过的苹果,问他:“这是什么?” 他如果能答对“是苹果”,就说明他学会了。
回到文章里:
所以,“有监督的表格机器学习任务”,翻译过来就是:“给AI看一大堆带标准答案的Excel表格,让它学会根据表格里的信息,去预测一个分类结果或者一个具体数值。”
近年来,随着深度学习的迅猛发展,计算机视觉与自然语言处理等领域取得了突破性进展,深度神经网络(DNN)能够从原始输入中自动提取语义表征(representation),不仅提升了模型的泛化能力,还促进了跨任务的知识迁移。这种能够建模复杂特征交互关系、学习层次结构的能力,使得将深度学习方法应用于表格数据成为研究热点。
整个结构就像一个倒过来的树,或者你的思维导图。它非常直观,容易解释,所以曾经是处理表格数据的王者。
现在我们再来读一遍这段话,你会发现它清晰无比了:
近年来,DNN(多层人工大脑)在处理图片和语言上很厉害,因为它能自动从数据里学会理解和表达数据的内涵(表征能力),还能举一反三(泛化能力)和跨界学习(跨任务知识迁移)。它能自动发现数据间的隐藏关系(复杂特征交互)和层层递进的规律(层次结构),所以大家觉得它也应该能搞定表格数据。
在十多年前,大家就用一些早期的、笨拙的DNN技术(堆叠式…)来处理表格,主要用来简化数据(降维)和画图给人看(数据可视化),但效果始终打不过老王者“树模型”(做是/否决策的流程图)。
但是,现在DNN技术本身变强了,在猜你点不点(点击率预测)、抓坏人(异常检测)、**猜你喜欢(推荐系统)**这些方面进步巨大。所以DNN在处理表格数据这件事上迎来了“文艺复兴”,性能已经快要赶上甚至超过“树模型”了!
为了实现强大的“表征能力”,模型必须具备处理“复杂特征交互”的本领,但这只是它众多本领中的一个,尽管是非常重要的一个。
| 对比维度 | 复杂特征交互 | 表征能力 |
| 本质 | 数据中的客观现象。是数据列之间隐藏的、非线性的关联。 | 模型的主观理解能力。是模型学习、概括、提炼数据精髓的本领。 |
| 中心 | 以数据为中心。它存在于数据中,不依赖于模型。 | 以模型为中心。它是模型的一种属性,有好有坏。 |
| 关系 | 是模型需要去发现的目标。 | 是模型用来发现目标的工具。 |
| 举例 | “30岁男性”+“购买尿布”→ 大概率会买啤酒。 | 模型在内部自动生成了一个叫“年轻父亲”的用户画像(这个画像就是一种表征),并把这个画像与“啤酒爱好者”关联起来。 |
专用方法

模块原文:
这个模块的目标是“兼容性评估”和“资源评估”。
模块原文:
这个模块的四大目标,就是由这四条具体操作实现的:
模块原文:
这个模块的核心目标是实现平稳、高效的数据同步。
模块原文:
这个模块的目标是“双重验证,确保万无一失”。它通过两条路径来达成这个目标:
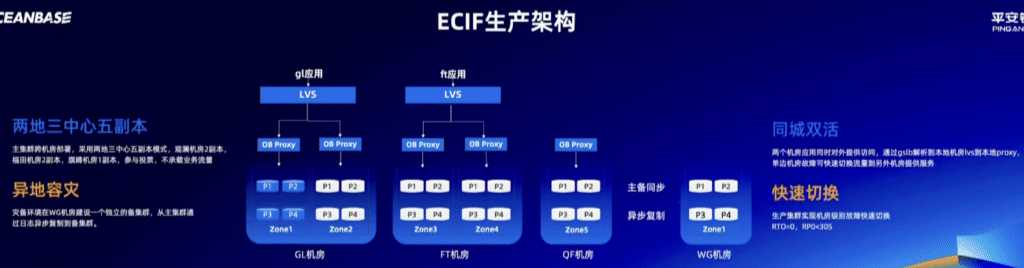
ECIF生产架构 (银行客户户口本的在线系统架构)
核心目标:极致的高可用和数据安全。
在主集群内部(深圳的三个机房之间):
从主集群(深圳)到备集群(上海):
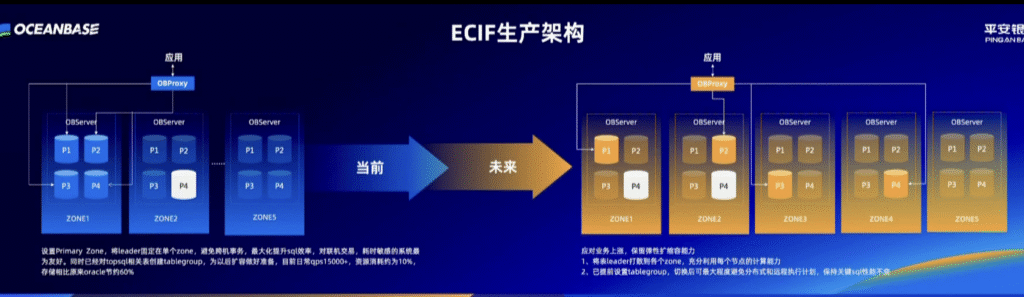
这张图的核心思想是:从“为读优化”的集中式Leader架构,演进到“为写和扩展优化”的分布式Leader架构。
1. 架构描述:
2. 这种架构的“好处”:
3. 这种架构的“潜在问题”:
1. 架构描述:
2. 为什么要这么演进?
3. 怎么保证性能不下降?
平安银行的ECIF系统架构演进,是一个深思熟虑的、分两步走的优化过程:
这个演进体现了架构设计的艺术:在不同的阶段,根据核心矛盾的不同,采用不同的策略,并为下一阶段的演进提前做好准备。
33.6s
more_vert